
|
Lewandowsky, Gignac, and Oberauer (2013) authored "The Role of Conspiracist Ideation and Worldviews in Predicting Rejection of Science" in PLOS ONE. (Paper here.) This study has many of the same features as their Psychological Science scam. In that study, they falsely linked belief in the moon-landing hoax to climate skepticism when in fact only three participants out of 1145 held both of those beliefs, and over 90% of climate skeptics in their sample rejected the moon-landing hoax. In the PLOS ONE study, we see the same broken conspiracy items, e.g. the New World Order item erroneously refers to the NWO as a group, the JFK item doesn't describe much of a conspiracy, the free market items are written from a leftist perspective, using proprietary leftist terminology. The validity of this study would be in doubt regardless of the results. A much more serious problem, however, is that there is bad data in the sample. Most consequentially, there is a 32,757-year-old, a veritable paleo-participant. (Data here.) There are also seven minors, including a 5-year-old and two 14-year-olds, two 15-year-olds, and two others. They were alerted to the presence of the minors and the paleo-participant over a year ago, and did nothing. This would be a serious problem in any context. We cannot have minors or paleo-participants in our data, in the data we use for analyses, claims, and journal articles. It's even more serious given that the authors analyzed the age variable, and reported its effects. They state in their paper: --- "Age turned out not to correlate with any of the indicator variables." This is grossly false. It can only be made true if we include the fake data. If we remove the fake data, especially the 32,757-year-old, age correlates with most of their variables. It correlates with six of their nine conspiracy items, and with their "conspiracist ideation" combined index. It also correlates with views of vaccines – a major variable in their study. See the graph below. 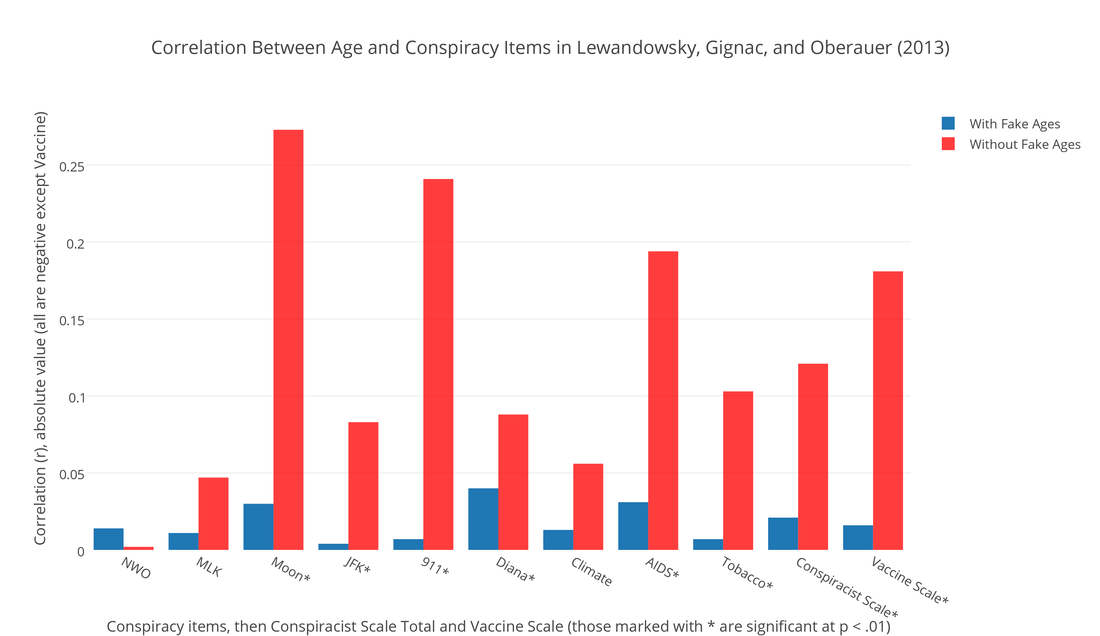 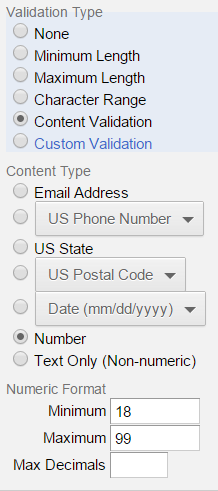 See the full Plotly graph here. (By "fake ages", I mean that the 32,757 age is presumably fake, and I would assume the 5-year-old is not in fact a precocious 5-year-old who somehow got through the uSamp.com / Qualtrics participant pool that the authors used. As we get into the 14- and 15-year-olds in the sample, it's easier to imagine these might be true ages, and I think we become very concerned about the possibility of actual minors in the sample.) (As noted in the graph, all the correlations between age and conspiracy theories were negative, perhaps contrary to common stereotypes.) It's highly unusual to have out-of-range ages, especially five-digit ages, in survey data obtained electronically. Any of the online survey systems we use will validate the age field for us. That is, they won't accept an invalid age. No one should be able to say that they're 5 years old, or 32,757, and proceed to participate in an IRB-approved psychology study. The authors apparently used Qualtrics. I use it all the time. When building a survey, you customarily set the age validation right there on the side panel, like so: What's even more concerning is that the authors reported the median age (43), and even the quartiles, in the paper. And as noted above, they analyzed age in relation to other variables. It's difficult to understand how any researcher would know the median age, quartiles, and correlations with other variables, but not encounter the mean age, which was 76. That mean would immediately set off alarms for any researcher using normal population samples. Any statistical software is going to show the mean as part of a standard set of descriptive statistics. (The mean after removing the fakes and minors, is 43.) It's also hard to imagine how they did not notice the 5-year-old, or the 32,757-year-old, which is the outlier responsible for the inflated mean age. Min and max values are given by default in most descriptive statistics outputs. That one data point – the paleo-participant – is almost single-handedly responsible for knocking out all the correlations between age and so many other variables. If you just remove the paleo-participant, leaving the minors in the data, age lights up as a correlate across the board. Further removing the kids will strengthen the correlations. What concerns me the most is that these researchers were alerted that their data was bad on October 4, 2013 and did nothing about it. A commenter posted directly on Lewandowsky's webpage where he had announced the paper, a mere two days after the announcement: "Additional problems exist as well. For example, one respondent claims an age of 32,757 years, and another claims an age of 5. Do you believe this data set should be used as is, despite these obvious problems?" Almost a year later, on August 18, 2014, I posted a comment directly the PLOS ONE page for their paper, and noted the bogus age data¹. They've known for a very long time that there is a 32,757-year-old in their data, along with a 5-year-old, two 14-year-olds, two 15-year-olds and two other minors, and they've known that they reported analyses on the age variable in their study. They did nothing. I think it's safe to assume that they've known for quite some time that the above-mentioned claim is completely false: "Age turned out not to correlate with any of the indicator variables." A 32,757-year-old will grossly inflate the mean and corrupt the deviation scores and SD – any trained researcher would know that this could severely impact any correlation analyses. Some of their other effects seem to hold, but the coefficients are smaller controlling for age. However, I would not take any of their findings seriously given that:
I don't understand how anyone could let a paper just sit there if they know the data is bad and specific claims in the paper are false. No credible social psychologist would simply do nothing upon discovering that there were minors in their data, or a five-digit age. I'd be running to my computer to confirm any report that claims I'd made in a peer-reviewed journal article rested on bad data, fake participants, etc. I wouldn't be able to sleep if I knew I had something like that out there, and would have to retract the paper or submit a corrected version. You can't just leave it there, knowing that it's false. Their behavior is beyond strange at this point. The best case scenario here is that Lewandowsky is the worst survey researcher we'll ever see. My undergraduates do far better work than this. This is ridiculous. There's more to the story. They also claimed "although gender exhibited some small associations, its inclusion as a potential mediator in the SEM model (Figure 2) did not alter the outcome." Gender cannot be a mediator between these variables, since gender is usually pre-assigned and somewhat fixed, so I don't know what they're talking about. In any case, gender is strongly associated with both views of vaccines and views of GMO. It is the strongest predictor of views of GMO, out of all the variables in the study. It remains so in an SEM model with all their preferred variables included. (The effects are in opposite directions – women are more negative on GMOs and more positive toward vaccines than men.) In any case, something is very wrong here. The authors should explain how the 32,757-year-old got into their data. They should explain how minors got into their data. They should explain why they did nothing for more than a year. This is a very simple dataset – it's a simple spreadsheet with 42 columns, about as simple as it gets in social science. It shouldn't have taken more than a few days to sort it out and run a correction, retraction, or whatever action the circumstances dictated. These eight purported participants allowed them to claim that age wasn't a factor. It allowed them to focus on the glitzy political stuff, allowed them to focus on finding something negative to pin on conservatives. They don't tell you until late in the paper that conservatism is negatively correlated with belief in conspiracies – the exact opposite of what they claimed in the earlier scam paper that APS helped promote. Also note that we already know from much higher quality research that Democrats are more likely than Republicans to believe in the moon hoax, though it's a small minority in both cases (7% vs. 4%), and that Democrats endorse every version of the JFK conspiracy at higher rates. I think some journals might be unaware that the pattern of these conspiracy beliefs across the left-right divide is already well-documented by researchers who have much higher methodological standards – professional pollsters at Gallup, Pew, et al. We don't need junky data from politically-biased academics when we already have high-quality data from professionals. Which brings us back to the previous paper. APS extended that scam in their magazine, fabricating completely new and false claims that were not made in the paper at all, such as that free market endorsement was positively correlated with belief in an MLK assassination conspiracy and the moon-landing hoax. Neither of these claims is true. The data showed the exact opposite for the MLK item (which we already knew from real and longstanding research) – free market endorsement predicted rejection of that conspiracy, r = -.144, p < .001. And there was no correlation at all between free market views and belief in the moon-landing hoax, r = .029, p = .332. APS just made it up... They smeared millions of people, a wide swath of the public, attaching completely false and damaging beliefs to them. They've so far refused to run a correction. It's unconscionable and inexplicable. The Dallas Morning News has much higher standards of integrity and truthfulness than the Association for Psychological Science. I don't understand how this is possible. This whole situation is an ethical and scientific collapse. I'm drafting a longer magazine piece about this and related scams, especially the role of journals and organizations like APS, IOP, and AAAS in promoting and disseminating fraudulent science. This situation is beyond embarrassing at this point. If anything were to keep me from running the magazine piece, it's that it's so embarrassing, as a member of the field, to report that this junk can actually be published in peer-reviewed journals, that no one looks at the data, and that a left-wing political agenda will carry you a long way and insulate you from normal standards of scientific conduct and method. This reality is not what I expected to find when I chose to become a social scientist. I'm still struggling to frame it. Normally, the host institution would investigate reports of fraud or misconduct, but the system appears to be broken. Lewandowsky has not been credibly investigated by the University of Western Australia. They've even refused data requests because they deemed the requester overly critical of Lewandowsky. That's stunning – I've never heard of a university denying a data request by referring to the views of the requester. UWA seems to have exited the scientific community. Science can't function if data isn't shared, if universities actively block attempts to uncover fraud or falsity in their researchers' work. To this day Lewandowsky refuses to release his data for the junk moon hoax study. That's completely unacceptable, and there is no excuse for Psychological Science and APS to retain that paper as though it has some sort of epistemic standing – we already know that it's false, and the authors won't release the data, or even the national origin, age, or gender of the participants. It's ridiculous to have a system that depends entirely on one authority to investigate misconduct, especially an authority that will have a conflict in interest, as a host university often will. It puts everything on one committee or even one individual, dramatically reducing the likelihood of clean inquiries. The way journals and scientific bodies have tried to escape any responsibility is unconscionable, and completely unsustainable long-term. I'm enormously disappointed with people like Eric Eich and APS head Alan Kraut for failing to act against Lewandowsky's earlier scam, and in the latter case, for failing to retract the fabricated false effects in the Observer magazine. Falsely linking millions people to the belief that the moon-landing was a hoax was an incredibly vicious thing for the authors to do, and for APS to do. Eich, Kraut, and that whole body should take participants' welfare – and that of their cohort in the public at large – a hell of a lot more seriously. I'm stunned by how little they care about the impact such defamation can have on human lives, and how willing they are to harm conservatives. Imagine how a person might be treated if people thought he or she believed the moon landings were a hoax. We have a responsibility to conduct ethical research, and to not publish false papers. They inexcusably failed to act on the discovery that numerous claims in the earlier paper were false, that the sample was absurdly invalid and unusable, and that there are likely minors in the Psychological Science data (the authors said in the paper that their cutoff age was 10, and neither the journal nor APS have responded to me on that issue, nor have they released the data – Lewandowsky refuses to release the data, and removed the age variable and lots of other data from the data file they've made available. Refusal to release data should lead to the automatic retraction of a paper.) I'm very confused by the lack of concern about minors in the data. I don't know if this is controversial, but we can't have minors in our data. This is true at several levels. First, we would need specific IRB approval to have minors participate in a study – the study would have be focused on children, not some web survey asking about three different assassinations. Second, we don't want minors in our studies for scientific reasons – we don't want to make claims about human behavior, claims that are implicitly centered on adult human behavior, based on non-adult data. Third, it's illegal to secure the participation of minors in research without their parents' consent. This PLOS ONE study purportedly used an American sample, and I think the same legal concerns would apply in Australia. I'm still stunned that APS doesn't care about minors in the Psych Science data – that was something I'd expect any journal to care a great deal about. The ethical issues are much larger than those we normally face. If the minors in the data are real, that's a problem, and we couldn't use them. If they were adult participants who gave fake ages, then that's also a problem, and we couldn't use them, certainly not in analyses involving age. If they were not participants at all, then that's obviously a problem as well. The authors should explain how this data came to be – they should've done this over a year ago. In any case, I hope that PLOS ONE makes a better showing than APS, and I'm confident they will. They know about the issue, and are investigating. We can't have minors and 32,757-year-olds in our data, and we certainly can't make false claims based on such bad data. Enough with the scams. ¹ NOTE: I just added (Jan 8, 2015) the information about the October 4, 2013 disclosure of the minors and 32,757-year-old. Brandon Shollenberger was the whistleblower (username Corpus in that comment on Lewandowsky's website.) I've always known that I was not the original discoverer of the minors and the paleo-participant – my earlier draft stating that the authors knew since August 18, 2014 was charitable. In fact, I wasn't the first person to point any of the major issues with Lewandowsky's recent publications. It was people outside of the field – laypeople, bloggers and the like, who discovered the lack of moon hoax believers in the moon hoax paper, who pointed out that the participants were recruited from leftist blogs, that they could be anyone from any country of any age, none of which has been disclosed, etc. Throughout this whole saga, it was laypeople who upheld basic scientific, ethical, and epistemic standards. The scientists, scholars, editors, and authorities have been silent or complicit in the malicious smearing of climate skeptics, free marketeers, and other insignificant victims. I was late to the party. Also note that this business has been going on for some time. In 2011, Psychological Science published a bizarre sole-authored Lewandowsky paper where he investigated whether laypeople project the pause in global warming to continue. It's one of the strangest papers I've ever seen. He had two graphs/conditions – one of stock prices and one of global temperatures. He touted a significant difference in the slopes participants extrapolated onto the graphs – they evidently projected a higher slope to the temps compared to the stock prices. This is supposed to mean something, apparently. But...ah... the graphs were labeled: - Share Price SupremeWidget Corporation - NASA - GISS An obviously fake corporation name vs... NASA. I don't understand what's happening here. I feel like I stepped into something I fundamentally do not understand. Psychological Science?
66 Comments
The New Yorker has a nice article about our BBS paper on the lack of intellectual diversity in social psychology.
I cringe a bit at the title: Is Social Psychology Biased Against Republicans? This was never about political parties, and the lack of diversity goes much deeper than even political philosophy (conservative, liberal, libertarian -- that level of analysis). It goes down to basic assumptions about free will, the force of situational and nonconscious factors, and the various assumptions of one subculture in this place and this time -- American white academic liberal culture, which I see as a distinct culture, one culture in a constellation of them. I don't think there's anything particularly terrible about that culture -- I think there are a number of things to admire about it. But the unstated assumptions of that culture have shaped -- and sometimes invalidated -- social science research in myriad ways. Political bias is one of the major facets of what has happened, but it's not the whole story. Treating political parties as the level of analysis makes it much less interesting, and a bit tawdry. The explosion of partisanship in America is one of the sadder facts of our day. We see it everywhere. I'm not interested in political parties. I'm interested in science and in how we do science. I'm interested in the different ways we can frame research, and how our choices impact the results. Lately, I'm also interested in fraud cases, but just barely. One of the worst things about fraud is that it's boring -- it leaves us with nothing to talk about, no findings, no effects. I fight the fraud because of a baseline commitment to integrity in science, but I'm more interested in methods and validity, which is what we discuss in our BBS paper. Anyway, my conversation with Maria Konnikova had a couple of bonuses. I learned that Walter Mischel accounted for trust in adults in his famous marshmallow studies. I need to rewrite that post. And I learned of a very special babka place in NYC: Breads Bakery. I need to go there, stat. Next time I'm at the X with OG, or just in NYC. The biggest thing I learned from Seinfeld was the existence of babkas. I finally found sound at Zabar's a couple of years ago, but it sounds like Breads is a very serious situation. Interesting work by Krapohl, et al. in PNAS. I love twin studies. They look comprehensively on the heritability of various factors that contribute to academic achievement, particularly performance on the British* GCSE exams administered during high school.
They report that scores are 62% heritable, and that the different traits are from 35 - 58% heritable, with intelligence being the 58% figure. Their other traits were "personality", self-efficacy, well-being, etc. We'll have to look at the paper itself to see what they mean by personality, and what specific traits do the work. I'm guessing they mean Big Five personality, and that conscientiousness will be one of the major factors. (Openness to Experience often shows up as an important Big Five trait for academic achievement, but it's mislabeled – on its face, it's more about urban sophisitication, intellectualism, or urban liberalism than openness at a pure psychological level of analysis. We'll have data on this soon.) What does it mean for something to be "X% heritable"? I think this should be spelled out more clearly in news reporting of heritability studies, because I don't think the public will generally know what such statements represent. It is almost certain to mean that X% of the variance in Y (in this case, academic achievement/test scores) is accounted for by genes, by one's genetic inheritance. This is commonly expressed as R-squared in linear regression. 35 - 58% are huge figures for percent of total variance explained. We almost never see such large figures. To get the correlation, r , just take the square root of .35, .58, etc. The square root of .58 is .76. That's a huge correlation. What does it mean to say that X% of the variance in one variable is explained by variance in the another variable – what does it really mean, down to its bones? That's complicated, and modern language – English or any other – is not well-suited for describing the nature of such statistics in a sentence or two. Something that gets lost how we express such statistics is the reality of exceptions, and the number of such exceptions. Also, people often convert correlations to probabilities, which is completely wrong. That not what correlations are. A .76 correlation between X and Y does not imply – at all – that if a person is high on X, they're likely to be high on Y. And in this case, the particulars of which genes/alleles do the work, or which sets and combinations, will probably matter a great deal. They'll have different implications for the heritability of these outcomes and traits. We don't know all the details yet. I think the intersection of genetics and environment is extremely interesting, as is the intersection between genetics, environment, and willpower/self-regulation (which is itself partly heritable...) And the intersection between genetics, environment, willpower, and ideas. What does that mean? Ideas will be folded under "environment" for most purposes by most researchers. People are exposed to radically different ideas in different settings, eras, and cultures. We know almost nothing about the force of ideas. It has not received nearly as much research attention as things like income, race, genetics, etc., probably because those things are easier to measure. What's the impact of repeated exposure to the Reverend Dr. Martin Luther King Jr.'s I Have a Dream speech? Or Obama's speeches? Or Oprah, Feynman, Rand, Cyrano de Bergerac, The Shawshank Redemption, etc.? How sticky are they? How much are they remembered and used by those exposed to them? I suspect the ideas we're chronically exposed to by our parents and teachers will have more impact – the implicit and sometimes explicit beliefs about the world, the feasibility of success or happiness (which don't have to be the same), etc. But who knows – the ideas we get from books and movies might have a large impact. We capture some ideas in the form of worldview measures like belief in a just world, external vs internal locus of control, belief in free will vs. determinism (see Vohs & Schooler), dispositional optimism, or just cultural psychology. I think we've just started to explore that whole area, even if some of the measures have been around for a while, and I don't think we've done much from a developmental standpoint to track exposure to and assimilation of certain ideas throughout childhood (I've always envied developmental psychologists, and I think that social psychology could probably make a quantum leap if we all stopped what we were doing and dived into developmental psychology for two years, read everything we could, then reapproached our research questions.) This has always lurked in the corner as a weakness in how we approach genetics and evironment. We study, necessarily, the status quo, the world as it is, the world as we find it. Then we make inferences about the role of genetics and environment in X, Y, or Z. We declare that academic achievement is "58% heritable" and people will run around saying that as though it's a stable, fixed truth, like the acceleration of gravity on earth (even though the researchers don't necessarily think of it that way.) But what if the environment were different? What sorts of things about the environment could be fundamentally different than the environment(s) that existed for the participants at the time and place the researchers conducted their study? Ideas could definitely be different. And some ideas might interact with the phenotypes at issue. And some important ideas might not even exist yet. I think that will be a very interesting area to explore in the coming decades. I don't mean to say that particular ideas and values will definitely have a huge impact on the outcomes we normally focus on – reality is whatever it is, and I don't know what it is. This is what science is for – to find out. This is potentially very rich – ideas vary in structure, content, source, and many other ways. Exposure to and embrace of ideas can vary in many similar ways. A slightly related development: For decades, we thought Mischel's marshmallow studies represented a finding where children with more self-regulation, or self-regulatory capacity, fare better as adults – and that we could capture this when they were very young, like 4-5 years old. And the basic finding might still be true. But now we have innovative research that suggests that the credibility of adults might have been a factor. When an adult tells a child that if they refrain from eating a treat, they will get a bigger reward in the future, whether they believe the adult should matter. Some children might be more exposed to less credible adults – they might be lied to more. They might not take for granted that some dude in a lab coat is telling the truth. In that case, it would be a better strategy to just eat the treat in front of them while they can, and not pin their hopes on an adult being trustworthy. If that drove the Mischel results, and if such children were more likely to be low-SES, than it wouldn't necessarily be a story about self-regulatory capacity (though it still could be, in a couple of ways.) It could just be that a low-SES childhood predicts a low-SES adulthood, and that low-SES children were less likely to trust adults' promises, given their experience. (Thankfully, last time I checked, parents' income accounts for only 25% of the variance in childrens' adult income in the US, so the idea that environment is destiny is simply false. It's usually lower for daughters, which could be explained by cultural changes.) It's a fascinating issue, and it also touches on the need for more diversity in social psychology (and all branches of research psychology.) The idea that the children from low-SES homes might not trust adults as much might not occur to a lot of researchers who never grew up in such settings. We need more Mexicans, more blacks, more white people who grew up poor, definitely more Asians. And like we argue in our BBS paper, more intellectual diversity, more people who depart from the prevailing white liberal narrative. The best argument for biodemographic diversity is that it leads to greater diversity in ideas and assumptions about human behavior and the factors that drive it. I for one don't care about racial diversity for esthetic or reparative justice reasons – I care about it because it gives us a broader set of intuitions and experience, and ultimately better and longer-lasting research. How is this related to my starting point, the genetics and academic achievement study? Well, it would be a very Joe move for it to not be related at all. I start in one place and end up somewhere else all the time. But it's related here in that what many people took to be a proxy measure for a heritable trait – self-regulatory capacity at age 4 or 5 – might have actually been a measure of an environmental variable. It might have been about what the children had learned about the trustworthiness of adults (and learning is environment for our purposes.) There are lots of ways we can make that type of mistake, even if we conclude that in this case the basic finding still holds, which we might yet conclude. We can mix up conceptual opposites like nature and nurture by making bad assumptions, based on the narrow cultural firmament of contemporary academia – the assumptions of urban white liberals, in essence. There's nothing wrong with being urban, white, or liberal, or all three – my point is simply that this is one culture in a constellation of cultures. Anyway, I love twin studies like Krapohl's. * The drama over the exams in Harry Potter is more easily understood if you know about the British exam system, the A-levels, etc. Americans have no equivalent, even in states that mandate exams for high school graduate. This is interesting. Lewis and Curry estimate equilibrium climate sensitivity (ECS) at 1.64°C. That's remarkably low. If it turns out to be true – and it seems like we won't know the true value for ECS for another decade or longer – then AGW would have been largely overstated. The estimates constantly change, which is frustrating.
I can't evaluate their methods. I'm curious to read any critiques by other climate scientists. ECS is the long-term change in temperature from a doubling of atmospheric CO2. It's arguably the most important fact or estimate in the AGW issue. Ultimately, this is what anthropogenic warming is about. I think the baseline is the pre-industrial level, for which I've seen different estimates. I think it was 280 ppm. Now we're around 400 ppm. A doubling of the baseline would be 560 ppm. I have no idea when we're supposed to hit that. One of the things that surprises me about AGW skeptics and lukewarmers is that they don't seem to worry about the future consequences to themselves if they're wrong. Most of them aren't elderly, so they'll likely be around for decades. If AGW turns out to be a serious problem, I expect skeptics to be pilloried. So it's ballsy to be a skeptic – I won't be surprised by violence against them in 2050 if warming becomes a problem. It's also ballsy to be a climate scientist who offers low estimates of ECS. We haven't yet built a rational civilization when it comes to science and politics. An honest scientist who offers low estimate of ECS which turn out to be wrong will be savagely attacked. They'll be savagely attacked even before we discover whether they're right or wrong. So I think it's remarkably brave of them – being wrong on this issue is so risky, not just to themselves, but to the world. It would weigh heavily on me if I were a climate scientist. I'd have to quadruple-check the data, the analyses, and think very deeply about the validity of the methods and framework. I'd be terrified to offer estimates of ECS. It would feel like so much responsibility. At the high end, AGW could do serious harm to lots of people (well, they'd be able to see it coming decades in advance, so that might reduce the harm) The fact that the estimates always change would give me pause, because it would imply that my estimates would change, or at least be replaced by others' future estimates using new and better methods, where the "future" could be next year. The epistemology or meta-epistemology of ECS looks very tough from the outside looking in – if the estimates are always changing, what does this mean about the methods used to generate them? Or the nature of our knowledge of climate circa 1990 - 2014? Thankfully, they've tended to go down, like from IPCC4 to IPCC5, or at least the low end of the range has gone down. It's odd. We don't keep revising Planck's Constant or our estimate of the acceleration of gravity on earth, though admittedly these aren't the best analogies. It's just tough to know what to do with ECS estimates, because we know they always change. That's the one thing we know about them. This implies that we should expect them to change in the future, until we know something that tells us to stop expecting that. This is great work:
"As expected, across these experiments, the researchers found that the more people smiled, the happier they reported being. But only some people. Surprisingly, for a section of the population, smiling actually reduced well-being. The more these people smiled, the less happy they were. This is like finding that there are some diners who, after consuming a four-course meal, feel less full!" It makes perfect sense to me, and it's related to what I told The Chronicle of Higher Education a while back, that some people don't dispositionally approach happiness the same way. This finding is more at the implicit and affective level, but I wouldn't be surprised if it corresponded to a different broad disposition toward happiness. For example these might be high-meaning people, less affectively driven. It also something I plan to add to my Media Tips page: Many main effects are misleading. Some main effects are false for the majority of the population, meaning that an effect of the form X causes Y will often only be true for a minority of people. That's not the case here, but we still see a significant population for whom a famous effect does not hold, and in fact is reversed. Significant correlations between X and Y do not require that X predict Y in the majority of cases, or that being high in X (assuming a continuous variable now, like a personality trait) means one is likely to be high in Y. A significant correlation does not mean that at all. It can be driven by 10% of the sample. I've developed some new statistics, new coefficients, to help clarify what a correlation actually represents in many cases. These will be detailed in some upcoming journal articles, hopefully. It would apply nicely to the example above, and the pencil-in-the-mouth experiments. A colleague perused the the Cook rater forums and sent me this example:
"I got one last night, though, that I thought was funny - I rated it as "Explicit >50%", because it *was* attributing all the warming to human GHG emissions. It just claimed there wouldn't *be* much warming, asserting that the IPCC had grossly over-estimated climate sensitivity & feedbacks. I had to look it up to see who the authors were - Michaels & Knappenberger. I laughed out loud when I found that out. :-D" Link here. Like I've said, we'll never lack for fraud examples here. They claimed in their paper that raters were blind to authors, which they'd have to be to conduct valid subjective ratings, but they weren't. They broke blindness all the time, even divulging the authors to each other in the forums, mocking them, e-mailing entire papers, etc. I'm not sure everyone knew they were supposed to blind to authors (and journal), or that the paper would subsequently claim that they were, or the crucial importance of independent ratings. They didn't even know what interrater reliability was. And of course the substantive nature of the above rater's decision – and of the coding scheme that empowered him – hits on other invalidity issues. I stopped going through the discussions a long time ago, because the initial evidence was clear and I'd rather just do my own research. I've repeatedly said "there's much more" and I meant it – I was confused by people who took me to be presenting an exhaustive set of evidence, or tried to recalculate the 97% based on removing the handful of psychology and survey papers I listed. I supplied a batch of evidence that I thought was more than sufficient and expected the journal or IOP to do the rest – the burden of validating the ratings lies entirely with the authors, not anyone else, but that's not possible at this point. A broader a point I'd like to briefly expand: There are no results. I'm getting other e-mails about them claiming the "results don't change" from the fraud or something like that – the e-mailers understand that this is absurd, but I think my report was too long, and some people might not read the whole thing. There aren't any results that could change, because there were never any results to begin with. There is no 97%. Or 99% or 82% or 10%. There's no percent, no numbers to evaluate. Normally we'd vacate the paper for fraud, which I assume will ultimately happen here, unless fraud is defined differently at ERL. Even absent fraud, there is no procedure known to science that would enable us to generate meaningful results here. Taking any number from their study is just roulette – the numbers won't be connected to any underlying reality. The results of a scientific study only have meaning by reference to the methods by which they were obtained. Results cannot be divorced from methods. They falsely described their methods, on almost every substantive feature. This means we no longer have results to speak of – we don't know what we have, because we don't know how the results were obtained. We have a vague sense, and we know that raters were never blind or independent, and that such features could not even be enforced given their at-home procedure and bizarre online forum. We know that we could never do anything with a subjective rating study that employed raters who had a profound conflict of interest with respect to the results. This was a subjective human rater study – the results were entirely in the hands of the raters, like the one we see up top, who were political activists rating abstracts on a dimension that would serve their political aims. We'd have to ignore decades of scientific research on cognitive biases, motivated reasoning, implicit and non-conscious biases, and our basic grasp of conflict-of-interest in order to take this seriously. I think a lot of people would assume this was a prank, maybe like Sokal's – a test to see whether a scientific journal would publish a consensus study based on lay political activists divining the meaning of scientific abstracts for their cause. No one has ever done this. There are no results here for several other reasons. If you run a casual search on "global warming" and just start counting papers, deciding whether they endorse AGW, even implicitly, that's not anything. It's not any kind of measure of a consensus, not by anyone's definition. Especially if you're including a bunch of social science, polls, mitigation papers, psychology, etc. (They said they excluded social science and polls. They're remarkably casual about the importance of the truthfulness of the methods section of a scientific paper. Scientists would not be nearly so casual.) And we can't calculate interrater reliability here because they broke independence, and their ratings are contaminated by other raters' feedback. A subjective rating study that can't generate interrater reliability estimates no longer has usable data. The lack of meaningful results here, the lack of validity, is multifaceted and impossible to resolve. One reason this isn't a measure of consensus is that you're giving some people far more votes than others. Each paper is a vote by this method. There are many obvious biases and weights this will impose, even assuming a neutral or valid search. Old men will get a lot more votes than others, and there will be many other large issues that real researchers would think through and account for. But the search is invalid too – it gives unacceptable results and was apparently never validated or tested. We could never go with a search that excludes everything published by Dick Lindzen since 1997. You just took away dozens of his votes, for unknown, arbitrary reasons. That discovery would stop researchers in their tracks – they would test and dig into the different results of different searches, and figure out what was happening, and what terms were needed to sweep up all the relevant papers. A study of consensus based on a literature search obviously depends critically on the validity and completeness of that search – if the search is bad, it's over. Knowing what we know about this study and the search, there's nothing we can do with the data. Humans have an anchoring bias, and there's a small epistemological dysfunction in some quarters of science where people think that because something is published, or because it was peer-reviewed, it must be somewhat valid or have some kind of legitimacy (social psychologists call this "social proof".) That's not a survivable claim, and it's important to not let those sorts of biases affect your judgment of published studies. There's nothing we can do with this study. Someone would have to reconduct the study, using valid methods and avoiding fraud, to generate any numbers we could use. There's just no way to get meaningful numbers in this case. And a reconducted study would have to be a very different study -- it wouldn't actually be a repeat of this design. The set of papers would be very different, given a validated and rigorous search procedure. It would have none of the invalid stuff, would include a lot of climate science papers that they excluded. I hope that illustrates my central point -- there's no way to generate results from this study, because the underlying data is invalid in multiple critical ways. Taking a number from the Cook study -- any number -- is just rolling dice. The number won't have any connection to the reality the study was supposed to measure. It's not clear that we can study a consensus by counting papers. We certainly can't just count papers without any weights, even if we have a valid search. Before we get there, we'd need some kind of theory of consensus, some reason to refer to literature as opposed to careful surveys of climate scientists, some specific hypotheses about what the literature gives us that surveys do not. There are a few possibilities there, but we'd need to think it through. A reasonable theory of literature-based consensus is probably not going to be temporally arbitrary – you won't weigh papers from 1994 as heavily as those from 2009. You won't count everyone's papers additively – you're not going to want to give Dick Lindzen 140 votes and some young buck 4 votes, based simply on paper count. You'll probably decide, based on theory, on a variable weighting system, where someone's 5th through 15th papers on attribution count for the most, but after 15 maybe you taper down the weights, limiting the impact of incumbency. You'd probably think about giving weight to heavily cited papers. You would not include most of the papers Cook et al included, like mitigation and impacts papers, for reasons detailed in the report (unless you could argue that impacts papers, say, carried epistemic information about human forcing. In that case, it would probably only be certain kinds of impacts research.) A paper-counting method is also extremely vulnerable to historical lag and anchoring effects. They went back to 1991, and there are an alarming number of papers from the early 1990s in their set. This sort of design will not detect recent advances that move the consensus in one direction or another. If we had a breakthrough in estimates of equilibrium climate sensitivity, something that changed the game, something that made scientists a lot more confident in the stability of the new estimates of ECS, ending all these years of constantly revised estimates, this breakthrough might manifest in three or seven papers over the last two years. If it were a significant downward or upward revision, it wouldn't be captured in the bulk of the literature back to 1991. The method is also vulnerable to Least Publishable Units practices and publication bias. The publication bias argument is popular with skeptics – it's an easy argument to make and a hard one to prove, which essentially leaves me with nothing much to say about it at this point. There are lots of other issues you'd have to think about, but even with rigor and qualified, unbiased raters who are blind and independent, in controlled environments like a lab, and only including climate science or attribution research, this could still all be useless and undiagnostic. We'd want to think about the difference between measuring consensus and measuring reality – the latter is what a meta-analysis does, in a sense. It aggegates findings, with strict methodological inclusion criteria, in an attempt to come to a credible conclusion about true effects (and effect sizes.) It doesn't measure consensus. People in most sciences generally don't talk about consensus much – look at the literature. For example, no one in my field is trying to get anybody to come to consensus or hold a bake sale or anything like that. Cook and company's claims about science as such being driven by consensus are strange – you'd probably have to do some serious empirical work to support such a sweeping positive empirical claim about so many fields. Consensus is unlikely to be a universally reliable, portable heuristic for reality across domains and arbitrary timepoints. You'd have to really dig in, and have an account for whether consensus will be epistemically diagnostic or reliable for climate science in particular. That's a very hard question. You'd want to consider that dissent in general will cost a person much more than assent or conformity, and there's some reason to believe that dissent in climate science is extraordinarily costly. You'd have to think about how you could account for this in any estimates of consensus, what weighting might be appropriate, whether the dissent in climate science represents ever-present base rates of less competent researchers or contrarian personality traits, or whether it represents something else entirely. For one thing, you'd probably be curious about the dissenters, and might want to talk to them and learn more about their reasoning. Some scientific truths won't be amenable to discovery by consensus-measurement, certainly not by the methods they used. Sometimes the only way to know something is to know it. Some problems in science might only be understood by 30 people in the world. Or 9. I don't know if that's true of any climate science problems, where the key issues are probably ECS and TCS. Some issues need very careful and advanced reasoning, real substantive engagement. Validity issues are like this. I've never dug into the controversy over climate models and their validity. That's a good example. A scientific method can be completely invalid, though this is probably less likely as time goes on. It's easier to do invalid science than valid science. I doubt the models are invalid, but if there is something fundamentally wrong with how climate models are used by climate scientists, and this leads to a systematic error in their estimates, then the consensus won't matter. If a field makes a fundamental, pervasive validity error, then it will just be wrong. This can definitely happen, though I think social science is much more vulnerable to this than climate science. More broadly, I don't think people have a full account of all the ways we can be wrong. We can be wrong in our fundamental frameworks, in all sorts of ways that we're not even trained to think about. I doubt that climate science is wrong, but these are the kinds of issues that you'd have to think about before giving much weight to a consensus. Consensus is not necessarily important or interesting – you have to make it so. And you definitely have to develop a valid way of measuring it. There might be better tools than consensus-measurement for public assimilation of scientific realities. For example, well-structured debates might be more informative and valid than consensus. I think there's some emerging research there. It's alarming that they were able to do this, and get published. The good news, such as it is, is that their false claims were in the area code of reality, as far as anyone knows. Valid studies find consensus in the 80s or maybe 90% (Bray and von Storch are good, as is the AMS report.) Some questions yield much lower estimates, but in general it's up there. 97% is inflated, and in this case the number had no real meaning anyway, just biased paper-counting from an invalid starting set. The inflated values might make a difference in policy choices, which is disturbing. We can't be so risky with science. It horrifies me when people shrug off such malpractice because it's only 10 or 15 percentage points off of reality. The danger of tolerating malpractice because the results are sort of close to accurate seems obvious, and the consequences of that kind of tolerance would likely extend well beyond climate consensus research. This amazing study reminds me of Flowers for Algernon:
"...the researchers recorded the EEG of human participants while they were awake and instructed to classify spoken words as either animals or objects by pressing a button, using the right hand for animals and the left hand for objects. The procedure allowed Kouider and his colleagues to compute lateralized response preparations—a neural marker of response selection and preparation—by mapping each word category to a specific plan for movement in the brain. Once that process had become automatic, the researchers placed participants in a darkened room to recline comfortably with eyes closed and continue the word classification task as they drifted off to sleep. "Once the participants were asleep, the testing continued but with an entirely new list of words to ensure that responses would require the extraction of word meaning rather than a simpler pairing between stimulus and response. The researchers' observations of brain activity showed that the participants continued to respond accurately, although more slowly, even as they lay completely motionless and unaware." Here's an update on the Cook 97% scam. They apparently have no answers.
Cook and some of his crew had a chat event at Reddit. Last I checked, they never addressed any substantive issues in the report, even though various people asked them about it. They don't argue against the fraud reports, the validity issues, nothing. Instead, they tried to attack me, or issued vague filibusters that had no bearing on anything happening here. To my knowledge ERL has yet to issue a statement or offer an explanation for the paper's comprehensively and substantively false description of its methods. To review, in their paper, they described their method as: "Abstracts were randomly distributed via a web-based system to raters with only the title and abstract visible. All other information such as author names and affiliations, journal and publishing date were hidden. Each abstract was categorized by two independent, anonymized raters." All three substantive features of their method are false. Raters were not blind to authors (or any of the other info.) Raters were not independent. Raters were not anonymized. They falsely described their methods. That is a very, very serious thing. There is no science without an accurate description of methods, and this paper, like all papers, was published on the assumption that they followed the methods they described. Normally the way science works, that's the end. Nothing else needs to be done by anyone. There are no results to evaluate if they didn't follow their methods. Why? Because valid results critically depended on those methods, and when people don't follow their stated methods, we don't know what they did and thus can't rely on the results. Climate science, or its journals, can't be an exception to this basic norm and epistemic requirement of valid science. Why would they be an exception? (This has nothing to do with the truth of AGW or the reality of a consensus -- this is about a fraudulent and invalid study.) This is not a pedantic issue. This was a subjective rating study where human raters read authored works and decided what they mean. Such a study could never be valid without blindness to the authors of the works they were rating, since knowing who the authors are is a multifaceted source of bias. Nor could it be valid without independent ratings – raters discussing their ratings in an online forum contaminates those ratings, exposing one rater's ratings to the views of other raters, and makes it completely impossible to calculate interrater agreement or reliability from that point forward. We have no valid numbers with respect to agreement – the crude percentages they strangely offered instead of proper interrater reliability coefficients don't mean anything given that the raters weren't independent. If we can't calculate interrater reliability, we don't have a study anymore. Having humans read complex text and decide what it means, what position it's taking on some issue, is a very special kind of research because it enables to researchers to create the data to a degree unparallelled in typical science, and the data is the result of subjective human appraisals of text, which is extremely vulnerable to bias, many sources of error, and in some cases the task is not theoretically possible or coherent. Such research demands great care, and won't be valid if things like blindness and independence are not observed. That these people gave themselves a category of implicit endorsement of AGW only exacerbates this. That they excluded papers they interpreted as taking no position on the issue, which were the majority, and calculated a consensus excluding all the non-polar papers, takes this all further from a universe governed by natural laws. They also thought they could just count papers, which is surprising – that papers, not people, are the unit of consensus – after excluding everything they excluded, and given all the obvious weights and biases that would be applied by a paper-counting method (research interest, funding, maleness, age, connections, whiteness, English-speaking, least publishable unit practices, # of graduate students, position as a reviewer, position as an editor, to name a few...) Moreover, in their online forum, the third author of the paper said: "We have already gone down the path of trying to reach a consensus through the discussions of particular cases. From the start we would never be able to claim that ratings were done by independent, unbiased, or random people anyhow." Maybe we should quote their methods section again: "Each abstract was categorized by two independent, anonymized raters." There appears to be no question that they knew, well before submitting the paper, that they had not implemented independent ratings, since as she mentioned, they were discussing particular papers in the forums the whole time. Yet, they still reported in their article that they used independent raters. What is this? The percentages for rater agreement that they report in the paper are voided because of this -- those weren't independent ratings, so there's no way to measure agreement between them. Nor can we assume that the fraud was limited to the forums, since the raters worked at home and could just google the titles of the papers to break blindness and see who wrote them. You can't perform this kind of study in such uncontrolled conditions – there's no way to credibly claim blindness here, which is crucial feature. In any case, they freely revealed authors of papers to each other on the forum, sometimes with malicious mockery if it was someone they had already savaged on their weird website, like climate scientist Richard Lindzen. It's incredible – they exposed the authors of the articles. They did so repeatedly and without censure, lacked any apparent commitment to blindness, and were e-mailing papers to each other, so it would be their burden to show the fraud was limited, if for some reason we cared that it was limited. Since they were e-mailing each other, they violated their claim of anonymized raters – they used their real names in the forum, had each other's e-mails, knew each other, were political activists from the same partisan website. That last fact also invalidates the study in advance – we can't have political activists rating scientific abstracts on their implications for their political cause. That's an obvious, profound conflict of interest, and empowers people to deliver exactly the results they desire. I want to stress that this is unprecedented. No one ever does this. It's too absurd and invalid on its face. Studies based on subjective human raters are a small fraction of all social science, and many researchers will never need such a design, but using subjective raters who desire a certain outcome and are in a position to deliver that outcome is simply not an option. For the defenders of this study, I think the absurdity of the design would be obvious in any other domain – e.g. a group of Mormon activists reading scientific abstracts and deciding what they mean concerning the effects of gay marriage, much less falsely claiming blindness to authors, falsely claiming to have used independent ratings, etc. If ERL or IOP want to argue that it's fine to use subjective raters who have an explicit, known-in-advance conflict of interest with respect to the outcome of the study, and thus their ratings, and who we can see in the forums gleefully anticipating their results in advance, bragging to each other that they've hit 100 abstracts without a single "rejection" of AGW, further biasing and contaminating others' ratings, posting articles and op-eds smearing "deniers" while they rated abstracts on the issue, and the leader of this rodeo telling the raters that this study was especially needed after another study found an unacceptably low consensus, again, while they were conducting ratings -- well, I'd really like to see that argument. It would break new theoretical ground. I'd normally say they need to talk to some experts in the subjective rating methodological literature, but in this case, you really don't. (I'm not aware of any study that has ever used laypeople to read and interpret scientific abstracts. This method is remarkable, since it seems implausible that laypeople would consistently understand specialized scientific abstracts. As scientists, we won't understand every abstract from our own fields, much less other fields. Some of the explicit violations of the claim of independent ratings in the forum were cases where raters didn't understand what an abstract was saying, which is easily predictable. Then of course others offer their interpretations, and the rater's subsequent rating is essentially someone else's rating. There is some research on bias and interrater reliability where scientists or doctors rated abstracts in their fields, as for a conference, as well as research on reviewer agreement in peer-reviewed journal submissions, which is historically quite low. Those researchers did not contemplate the idea of laypeople or non-experts rating scientific abstracts. You'd need a lot of training, I think, and it's unclear what the point of such a study would be, for reasons I detail in my report.) Relatedly, on the reddit forum all I saw were bizarre ad hominem attacks. One of the raters said I had no climate papers. That's goofy. You'd need deep climate science expertise to rate climate science abstracts, but you don't need it to point that out. The Cook paper isn't a climate paper – it's not about cloud feedbacks or aerosols. It's methodologically a social science paper, a subjective rating study, which is well within my area code. Calling out the fraud and invalid methods has no more to do with climate science than their paper does. For example, when someone says "Abstracts were randomly distributed via a web-based system to raters with only the title and abstract visible. All other information such as author names and affiliations, journal and publishing date were hidden. Each abstract was categorized by two independent, anonymized raters." ...you don't need to know anything about climate to read this, read the forums where they disclose the authors of papers and discuss their ratings with each other, refer back to the above text from their Methods section, and observe that they falsely described their methods. It might help to know what blindness means and why it matters for subjective ratings, but that's not hard. Moreover, while I think technical ad hominem is valid in some very restricted cases (like a probabilistic inference that non-experts are unlikely to be able to understand specialized scientific material, such that the burden is on them to show they can), it's never valid to respond to fraud reports by saying "He doesn't have any climate papers." You'd want to respond to the report, to answer it substantively. They did something very serious, and they need to answer for it. Others said my report needs to be published in a peer-reviewed journal in order to matter. Fraud is not normally debated in journals. I don't want to publish this in a journal (nor do I want any "climate papers".) It might be an example in a future publication, but why kill trees to point out fraud? We can actually see and know reality with our mortal eyes and mortal brains. And since the Cook paper made it through peer review, it's not clear that peer review should carry a lot of epistemic weight for the rational knower, at least in some journals or on some issues. My points are going to be true, false, valid, invalid, or some mix – whether they're published in a journal isn't going to tell us that. You can just read the arguments, consider the evidence, and decide – you don't need other people thinking for you. I could be a welder from Wyoming who just got out for good behavior – it would be remarkable for such a person to blow the whistle on a journal article, maybe worthy of a Lifetime movie, but it wouldn't change a damn thing. It wouldn't change anything about the Cook study, or the validity of my points. Nothing about me alters those realities. Journal publication might not even be a better-than-chance heuristic in such cases. This "consensus" epistemology is taken too far – people forget that consensus is only a heuristic, of variable and context-dependent reliability, not a window into reality. In any case, I reported it to ERL and IOP, and they should be able to handle it without my needing to write it up for a journal. The authors need to answer some very simple questions. There need to be answers. Without some sort of miracle redemption, some way of the fraud not being fraud, it should be retracted. I don't know if this a wild and crazy idea to some people, but science would mean nothing if we can falsely describe our methods (and use methods guaranteed to produce a desired outcome.) Cook responded to questioners by saying "The common thread in all criticisms of our consensus paper is that the 97.1% consensus that we measured from abstracts is biased or inaccurate in some way. Every one of these criticisms fails to address the fact that the authors of those climate papers independently provided 97.2% consensus. This is clear evidence that attacks on our paper are not made in good faith." This is bizarre. They may be counting on people not reading my report. I explicitly address this issue in the report, so his claim is false. Here are a few reasons why we don't care about the author self-ratings anymore: 1) We learned that Cook included psychology, social science, public survey, and engineering papers in their "consensus". This after they explicitly said in their paper that social science and surveys of people's views were not included as climate papers. Chalk up another false claim. But, since they included a bunch of invalid papers, this means their author survey included the authors of those papers. This in turn means we can know longer speak of the authors' self-ratings percentages – those figures have no meaning anymore, given that we don't know how many were from psychologists, sociologists, pollsters, and engineers. 2) I pointed out in the report that their counting method is invalid because they count mitigation and impacts papers that have no obvious disconfirming counterparts. For example, if an engineering paper counts as endorsement because it mentions climate on its way to discussing an engineering project, how would an engineering paper count as rejection? By not mentioning climate? If a paper about TV coverage of climate news counts as endorsement (in contradiction of their stated criteria), what sort of study of TV coverage would count as rejection? One that doesn't mention climate? An analysis of Taco Bell commercials? Where's the opportunity for disconfirmation? There's no natural rejection counterpart to such categorization (it won't matter if you find a mitigation paper that they counted as rejection -- this is about the systematic bias, and the endorsements will be far greater than the rejections here as a result.) This all means we won't care about the authors' self-ratings, because of this systematic selection bias in the method (anything that biases the selection of articles biases the subsequent pool of authors rating those articles.) I also pointed out that we can't validly measure consensus by excluding the vast majority of actual climate science papers that do not take polar positions of endorsement or rejection, which is what they did. Consensus cannot exclude neutrality. We can't assume that neutrality represents a consensus, as they do. And we probably can't count papers to begin with. This is all in the report. 3) Pointing at squirrels is never good when a study has been rebuked for fraud or invalid methods, both of which are the case here. You cannot redeem the malpractice in the first part of the study -- all their false statements about their methods, the invalidity and meaninglessness of their results -- by talking about a completely different part of the study. That's pure evasion. They need to answer for what they did. 4) There are serious questions about their literature search, such as how it excluded everything Dick Lindzen has done since 1997. There are no results without figuring out what's going on with that search, how it excluded all the modern work of a seminal lukewarm climate scientist. You can't just run a lit search based on a couple of terms and then declare that you've got a valid, representative sample of studies. No way. Science can't be so haphazard – you have to try. There's work involved. New methods need to be validated. We can't begin to talk about percentages and numbers without first establishing that our data is valid, this this literature search is valid (and dealing with all the other issues, the first of which is the fraud.) The search issue will interact with point 2 above. Validating the search will require careful thinking, testing, etc. Some of the methodological meta-analysis literature will have guidelines. How to do a valid search for this purpose is a nontrivial issue – nothing that happens after the search matters if the search isn't valid. You have to figure out if there are selection effects, what you're including, what you're excluding, especially with respect to your hypotheses, what happened to Lindzen's papers, and so forth -- you don't just run a search and start rating papers. This is science, not numerology. (The equivalent would be if some people rented a couple of hot-air balloons for a few days, took pictures of some clouds, wrote it up for a journal submission on cloud cover in North America, and we simply accepting their method without question. Science can't be that sloppy.) (And only 14% of authors responded to their survey, and they got about two votes each, which highlights the oddity of simply counting papers. I've already pointed out in my report many of the biases and potential weights that will be applied by a simple paper-counting method.) Cook's statement is also bizarre because of his conclusion. Saying that people who contest the validity of their ratings never address the purportedly similar results of the authors' self-ratings, and that this "is clear evidence that attacks on our paper are not made in good faith" is so strange. Evidence that people are not acting in good faith? Because they don't address some other part of a study? That's such a strange model of human psychology, and of how science works. They seem to have a remarkable immune system or strategy of not engaging substantive criticism, characterizing it as not in good faith, "denial", misinformation, etc. If genuine, it's a remarkable worldview. Another Cook tactic was to talk about other studies finding similar results. I was dumbfounded. When someone is referring to your false claims about your methods, and your invalid results, the subject under discussion is your study. Nothing else matters. There could be a thousand 97% papers. It wouldn't matter. That there is a consensus does not matter. The issue is the Cook study, its fraudulent claims, its invalid results. Fraud is fraud. We don't redeem fraud by talking about other people's studies. Some of those studies are almost as bad and unusable, like the one-pager, but that's beside the point. The true, meaningful consensus could be 99.997% – that won't matter here. (We also don't need this study to establish a consensus, just as we don't need a particular hockey stick paper to establish anthropogenic warming. We might consider that the case for the consensus likely weakens if this study is included.) It's incredibly disturbing to repeatedly see this kind of response from people who were published in a scientific journal. Not only did these people have no idea what they were doing, they betray no sign that they're aware of the basic norms of science, the importance of faithfully describing one's methods, why fraud is a serious thing, what it means to say that results are invalid, or how the existence of other people's studies won't intersect with or override the false claims made about one's own study. If their responses are being validated or accepted by ERL or IOP, we've got a much bigger problem. People might be justified in ignoring climate science if climate journals are fine with what Cook did. We wouldn't have any way of knowing that other research was valid, since climate papers would be much harder for us to evaluate. If ERL is fine with fraud, we wouldn't know what to do with any future ERL articles, or with the field as a whole. That's not anywhere we want to be. Some of the confusion or delay might be due to ERL's unfamiliarity with these methods, the need for blindness, independence, interrater reliability, probably a lack of awareness that they falsely described their methods. But those can't be issues anymore – if people don't get it, don't understand why a subjective rater study necessitates that the ratings be blind and independent, don't understand why this study destroyed our ability to calculate interrater reliability, etc. they can just consult some relevant experts in social science. Let me tell you something else. Some people are saying this paper won't be retracted because the journal is biased, or because it would look bad for Dr. Kammen (the editor), or because he works with the White House, that science is rigged. We need to cut the crap. I don't care who is who or how much power they have. This was fraud. Falsely describing one's substantive methods is fraud. This paper is invalid in ten different ways, but fraud is fraud. They have not answered for it. They apparently have no answers. If the relevant decisionmakers are thinking that they can just ignore this, or issue some PR blather, they need to think long and hard about what the hell we want science to be. They need to think long and hard about the long-term consequences of failing to retract fraud when the evidence of said fraud is so publicly accessible and straightforward. They might think about how far we have to throttle down our brains in order to believe that this study is remotely valid. They might think about what it will do to the reputation of climate science not only that this study was published in a climate science journal, but that it wasn't retracted when it was revealed to be fraudulent and multiply invalid. There are real consequences here, long-term impacts. We can't be this bad at science, this corrupt. We need to stand for things that aren't in a party platform. These people made a complete mockery of the institutions and safeguards that we take for granted. They torched them. Afterword: I think it's worth considering what could happen in the long-term if this nonsense were tolerated, if we couldn't get people to act against fraud if the fraud were politically convenient, in combination with all the conventional fraud and malpractice. Cultures and civilizations evolve in countless ways. The meanings and usages of words can change. There's no a priori hard constraint on this process. Science doesn't have to mean something like rational inquiry, or the systematic, reproducible validation of empirical claims or hypotheses, or any of our other definitions (in capsule form.) The word science could end up meaning something very different. For example, in the worst case, it could end up being used only ironically, as a term for scams. As it stands, we probably use the term too broadly -- science is very diverse, and the issues discussed above will be alien to many scientists. (The idea of gathering some political activists to "rate" scientific abstracts is far removed from most scientists' methods, and the type of fraud we see here is very different from prototypical fraud in cellular biology, for example.) I don't mean that what we've classically known as science would cease to exist -- that would likely require a large asteroid strike. I mean that science could plausibly evolve into a label for a corrupt and privileged subculture whose divinations are no more tied to reality than a day-old religion. In such a case, actual science as we mean it today would be called something else, perhaps interrogo, ρωτήστε, or bluefresh, and the professionals who practiced it would meet high standards -- the standards people expect of scientists today. I'm not saying this is likely -- I don't quite think it is. But I think it's plausible, and I'd caution you against underestimating the degree of change and evolution that human culture and language can experience, even in our lifetimes. I don't mean to make a trivial point about changes in terminology and phonemes. I mean to illustrate that continuing to generate garbage and fraud under the banner of science will despoil that banner. Circling wagons to protect such fraud and garbage is tautologically incompatible with our prior commitments to scientific integrity. In any case, nothing in life is assured -- not prestige, not funding, not an audience. I don't like being pragmatic about this, since I think idealism should dominate here. We like to say we stand on the shoulders of giants -- we might want to think about whether anyone will be able to stand on ours. Hi all. I'm working on a side project, and I ask for your help.
Have you been harmed by others' judgments or perceptions of you as a climate skeptic? Please send me your stories. Climate skeptic is broad and vague, but what matters here are others' perceptions of you as questioning human-caused warming, or questioning or doubting its future severity, and so forth. By harmed I mean things like discrimination at work or in business, or damage to personal relationships of all kinds, due to others' perceptions of you on this topic. For example, has it ever come up in a job interview or promotion? (Seems like it wouldn't come up, but there's a lot of variance in what happens in interviews, and sometimes people will just have casual conversations about whatever, and political or social issues can come up.) Are any of you stereotyped or marginalized as cranks, conspiracy nuts, "deniers", etc. in your workplaces? Have people ascribed any other views to you based on you being climate skeptic? Now I wonder about something more specific. Have any of the Lewandowsky scams come up yet in real life? For example, have has anyone assumed that you believed the moon landings were a hoax? Have people assumed that you don't think that HIV causes AIDS, or that smoking causes lung cancer? Have any of these specific issues popped up? Moreover, did people who know that you're pro-free market or an economic conservative (for Europeans, I mean an economic liberal) think that you dispute that HIV causes AIDS? The vector here is from the journal inexplicably publishing the Lewandowsky scam paper --> the various media outlets that covered it --> people read the articles and carry the false associations in their minds. For example, there were articles in Mother Jones, the New York Times, and countless other places, that repeated the false claims made by Psychological Science and Lewandowsky. I'm wondering to what extent it's out there in the streets, so to speak. There are 7 billion people on earth, and I think any false psychology findings ascribing beliefs to a large group of people and reported in the mainsteam media will have an impact on some number of people. Here are some examples of what I mean: You go out on a first date, or several dates, then the other person learns about a view you hold and they end it. This happens all the time on anything. They learn that you're an atheist and it's over (happened to me once.) Or that you're a Baptist. They learn that you're a liberal/Democrat. Or that you're a conservative/Republican. These are dealbreakers for extremely partisan people where a large part of their moral identities and self-concept is tied up in their political affiliation. You're at work and you say something about your views on human-caused warming, maybe minimize it's long-term impact. It has a chilling effect, and coworkers see you differently from that point on, think you're a nut, don't invite you to happy hour, etc. I'm guessing this is rare. In such a case, the coworkers would likely have to be very political and caught up in the "denier" narrative. I'm even more interested in cases where the Lewandowsky scams popped up, where someone said something like "Do you think the moon landings were a hoax?" or whispered to others that you dispute that HIV causes AIDS, after reading some junk article by Chris Mooney passing on the false findings. And again, this doesn't have to be about climate skepticism necessarily. The false associations about AIDS and smoking were linked to pro-free market views, not climate skepticism, but I think all this would likely be jumbled together in the minds of people who read a hit piece in the media. If you have any experiences you think are relevant here, please send me your stories. Thank you! 4.5 million hospital records were hacked, apparently by a notorious Chinese hacking group. I've been concerned about the security of medical records for years – the issue has been obscured by the huge business breaches like Target, Nieman Marcus, and now Home Depot (Russian hacking teams, usually based in Odessa, Ukraine.)
There's a basic structural problem right now with IT security. There aren't enough security experts to go around, and businesses and institutions often have no clue what they're doing. To secure computer records and networks, especially those that have any link to the internet, requires a lot of expertise and constant up-to-date awareness of threats and types of attacks. Think about all the doctor's offices and hospitals you go to. The small practices in particular are not going to have a clue about IT security – yet they're going to have a lot of sensitive information about you. Psychologists, psychiatrists, drug rehab facilities, etc – they have very sensitive records, but I'd not expect them to do a good job of securing them. If they've got PCs with web access, which they will, and those PCs are on a network with PCs that have your records, there's your vector. (And it will often be the same PCs...) I think it's best to assume our records are compromised. It's much easier to breach a medical practice than to breach Target. I think it's probably wise to extrapolate from all the breaches you hear about and assume there are a lot more. Security experts say this all the time. This means you might want to think about what you disclose when you complete all the forms these various places require. It might be wise to just tell a doctor or other professional something you think might be important about your medical history instead of putting it down on a form (though it still might end up in your file because they take notes and so forth – ultimately our medical records are going to have to be populated with medical information.) And when you're visiting unrelated practitioners, you don't need to disclose everything about your medical history, even though the forms ask for it – for example, if you're seeing a physical therapist for a bad knee, maybe you don't need to document your colon cancer or drinking habits, even though their intake forms ask about that kind of stuff (the forms are often boilerplate – they're not necessarily designed for the needs of the practice that uses them.) |
José L. DuarteSocial Psychology, Scientific Validity, and Research Methods. Archives
February 2019
Categories |
 RSS Feed
RSS Feed
